Deleting a Node in BST
A closer look at how Binary Search Trees remove nodes while carefully maintaining the search property that keeps the structure ordered and efficient.
The BST Invariant
A Binary Search Tree is not merely a collection of nodes. It is a disciplined structure governed by a simple invariant: for every node, values in the left subtree are smaller, and values in the right subtree are larger.
This invariant is what makes BST operations efficient. Searching, inserting, and deleting all rely on this ordering to navigate the tree in O(h) time, where h is the height. When we delete a node, we are not just removing memory — we are preserving order. The structure must continue to behave as a valid BST after the operation.
The Three Cases
Deleting a node in a BST is not complicated. But it is precise. There are exactly three structural possibilities.
Case 1: Leaf Node (No Children)
This is the simplest case. The node has no children. Removing it does not disturb the structure. We simply detach it from its parent by setting the parent's corresponding child pointer to null. The tree remains valid.
Before: After deleting 3:
5 5
/ \ / \
3 7 · 7
Node 3 is a leaf → simply remove itCase 2: Node with One Child
Here the node has either a left child or a right child, but not both. Deleting it means connecting its parent directly to its only child. The child takes its place. The BST property is preserved because the entire subtree under the child already satisfies the ordering constraint.
Before: After deleting 3:
5 5
/ \ / \
3 7 2 7
/
2
Node 3 has one child (2) → replace 3 with 2Case 3: Node with Two Children
This is the only case that demands deeper thinking. If we simply remove the node, we break ordering. So instead, we replace its value with a carefully chosen substitute, either:
- Inorder Predecessor: The maximum value from its left subtree, or
- Inorder Successor: The minimum value from its right subtree.
Why these? Because they are the closest values that preserve ordering. The inorder successor, for example, is the smallest value greater than the current node. By definition, it has at most one child (no left child), so after copying its value, deleting it reduces to Case 1 or Case 2.
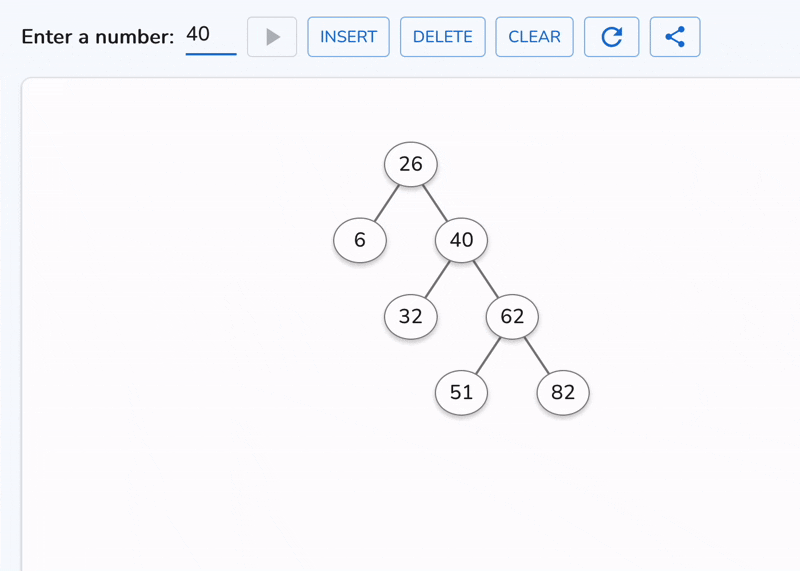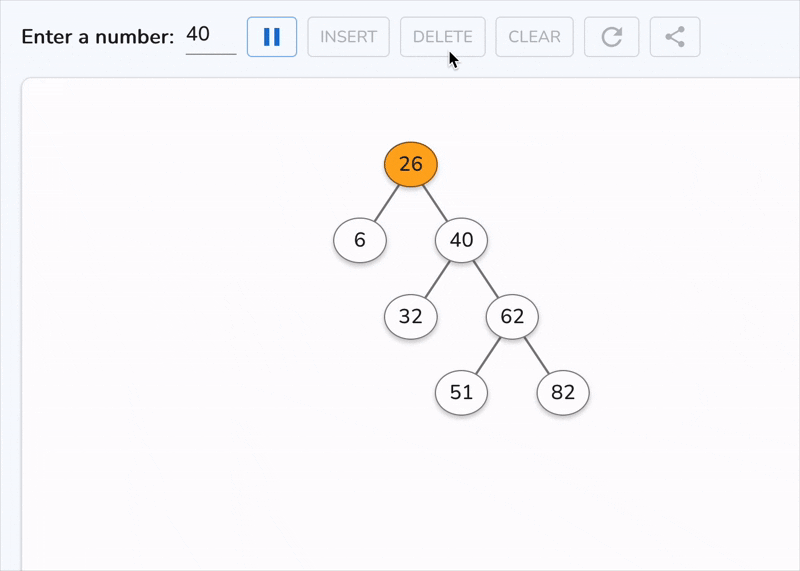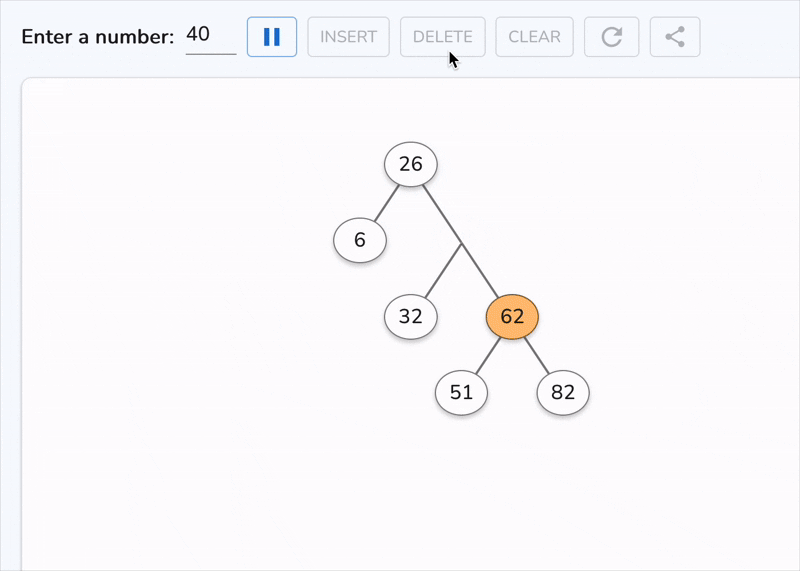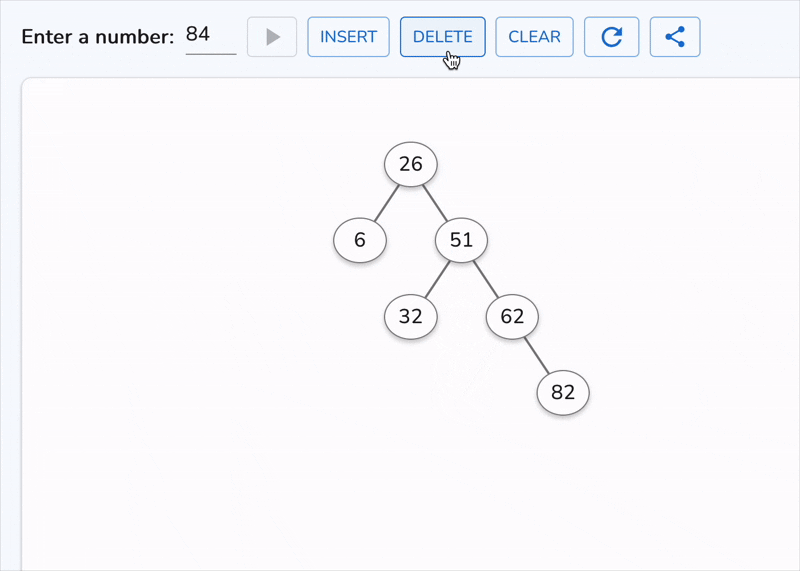
Time Complexity
The time complexity of deletion depends on the height of the tree:
Operation Balanced BST Skewed BST ──────────────────── ──────────── ────────── Find the node O(log n) O(n) Find successor/pred. O(log n) O(n) Delete and reconnect O(1) O(1) Total deletion time O(log n) O(n)
In a balanced BST, deletion is efficient at O(log n). But if the tree becomes skewed (degenerated into a linked list), operations degrade to O(n). This is precisely why self-balancing trees like AVL Trees and Red-Black Trees exist — they guarantee O(log n) height after every insertion and deletion.
Predecessor vs Successor
Both approaches produce a valid BST. The choice between predecessor and successor is often arbitrary — most implementations use the inorder successor by convention. However, consistently choosing one over the other can cause the tree to become unbalanced over time.
Some implementations alternate between predecessor and successor on each deletion to distribute structural changes more evenly. In self-balancing trees, this concern is handled automatically by the rebalancing mechanism.
Final Reflection
Most of the time, deletion is simple. Only when a node holds two subtrees do we need strategy.
By selecting a successor or predecessor as a replacement, the complexity reduces itself into one of the easier cases of deletion. The tree ensures that the structure remains consistent, and the search property continues to hold throughout the tree.
💬 Discussion
Sign in to join the discussion
Curious to Learn More?
Hand-picked resources to deepen your understanding


© 2025 See Algorithms. Code licensed under MIT, content under CC BY-NC 4.0